How to Prevent Twitter Api From Retrieving Same Tweets Again and Again
Easily-on Tutorials
An All-encompassing Guide to collecting tweets from Twitter API v2 for academic enquiry using Python 3
A step-past-footstep process from setting upward, accessing endpoints, to saving tweets nerveless in CSV format.
Table of Contents:
- Introduction
- Pre-requisites to Start
- Bearer Tokens
- Create Headers
- Create URL
- Connect to Endpoint
- Putting information technology all Together
- Saving Results to CSV
- Looping through Requests
1. Introduction
At the end of 2020, Twitter introduced a new Twitter API built from the footing up. Twitter API v2 comes with more than features and data you lot can pull and analyze, new endpoints, and a lot of functionalities.
With the introduction of that new API, Twitter also introduced a new powerful free production for academics: The Academic Research production rails.
The rail grants free admission to full-annal search and other v2 endpoints, with a volume cap of 10,000,000 tweets per calendar month! If y'all desire to know if you authorize for the rails or non, bank check this link.
I have recently worked on a data analysis research project at Carnegie Mellon Academy using the capabilities that this runway offers, and the power it gives you equally a researcher is mindblowing!
Yet since v2 of the API is fairly new, fewer resources exist if you lot run into issues through the process of collecting information for your research.
So, in this commodity, I will go through a step-by-step procedure from setting upwards, accessing endpoints, to saving tweets collected in CSV format to use for analysis in the futurity.
This article will be using an endpoint that is available merely for the Academic Inquiry track (Full-archive Search endpoint), just almost everything in this guide can be applied to any other endpoint that is available for all developer accounts.
If you do non have access to the Total-archive Search endpoint, you tin can yet use follow this tutorial using the Contempo Search endpoint.
It is recommended for you to use a Jupyter notebook when following this commodity, so every code snippet can be run in a separate cell.
two. Prerequisites to Starting time
First, we are going to be importing some essential libraries for this guide:
To be able to send your get-go request to the Twitter API, you need to accept a developer account. If yous don't have one yet, you can employ for ane here! (Don't worry it's free and you just need to provide some data about the research y'all plan on pursuing)
Got an canonical programmer account? Fantastic!
All y'all need to practice is create a project and connect an App through the developer portal and we are set to become!
- Go to the programmer portal dashboard
- Sign in with your developer account
- Create a new project, requite information technology a name, a use-case based on the goal you want to accomplish, and a description.
4. Assuming this is your kickoff time, choose 'create a new App instead' and give your App a name in order to create a new App.

If everything is successful, you should be able to encounter this page containing your keys and tokens, nosotros will employ 1 of these to access the API.
3. Bearer Token
If you lot have reached this step, CONGRATULATIONS! You are eligible to send your offset request from the API :))
Kickoff, we volition create an auth() role that will take the "Bearer Token" from the app nosotros merely created.
Since this Bearer Token is sensitive information, y'all should non be sharing it with anyone at all. If you lot are working with a team you don't desire anyone to have access to it.
So, nosotros volition save the token in an "environment variable".
In that location are many ways to practice this, you can check out these two options:
Surroundings Variables .env with Python
Making Use of Environment Variables in Python
In this commodity, what nosotros volition practise is we will just run this line in our code to ready a "TOKEN" variable:
os.environ['TOKEN'] = '<ADD_BEARER_TOKEN>' Just replace the <ADD_BEARER_TOKEN> with your bearer token from Twitter and after you lot run the part, delete the two lines. If you lot get any errors from this approach, try any of the links listed in a higher place.
Now, we will create our auth() function, which retrieves the token from the environment.
4. Create Headers
Adjacent, we will ascertain a office that will take our bearer token, laissez passer it for authorization and render headers nosotros will use to access the API.
v. Create URL
At present that we tin access the API, nosotros will build the request for the endpoint we are going to use and the parameters we want to pass.
The defined office above contains ii pieces:
A. search_url:
Which is the link of the endpoint nosotros want to access.
Twitter's API has a lot of different endpoints, here is the list of endpoints currently bachelor at the fourth dimension of writing this article with early admission:
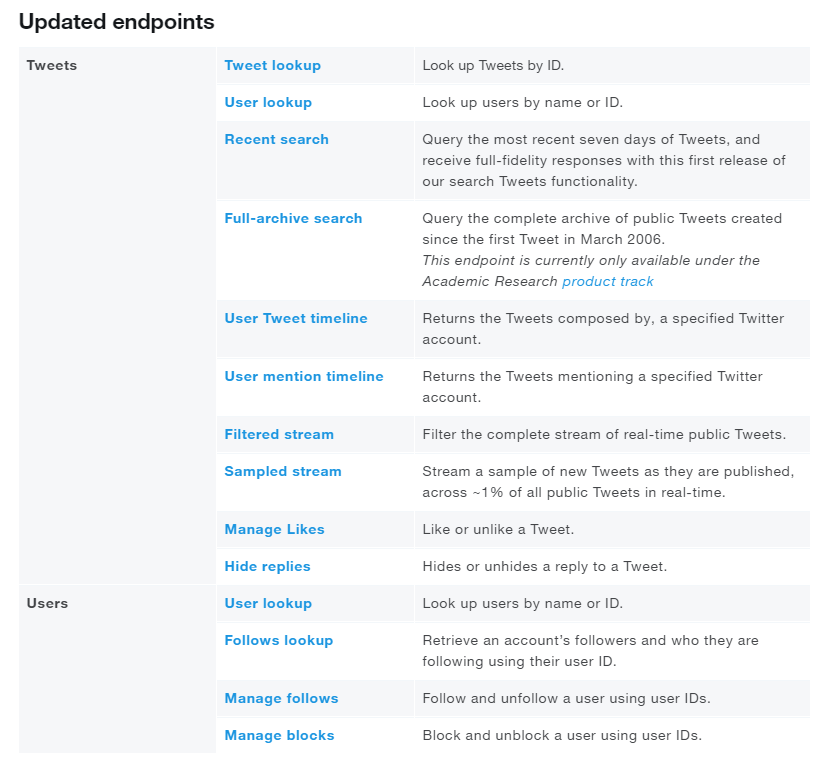
You can likewise find the full list and more information nearly each of the endpoints in this link.
For this article, since it is targeted towards Academic Researchers who are perhaps trying to benefit from Twitter's new production, nosotros will exist using the full-archive search endpoint .
B. query_params:
The parameters that the endpoint offers and we can use to customize the request we want to send.
Each endpoint has unlike parameters that nosotros tin can pass to it, and of course, Twitter has an API-reference for each of them in its documentation!
For example for the total-archive search endpoint that we are using for this commodity, you can find the list of query parameters here in its API Reference page under the "Query parameters" section.

We can decompose the query parameters above in the part we wrote to three sections:

1. The get-go four parameters are ones we are decision-making
'query': keyword,
'start_time': start_date,
'end_time': end_date,
'max_results': max_results, 2. The next 4 parameters are basically us instructing the endpoint to render more information that is optional that it won't return by default.
'expansions': 'author_id,in_reply_to_user_id,geo.place_id',
'tweet.fields': 'id,text,author_id,in_reply_to_user_id,geo,conversation_id,created_at,lang,public_metrics,referenced_tweets,reply_settings,source',
'user.fields': 'id,proper noun,username,created_at,description,public_metrics,verified',
'place.fields': 'full_name,id,country,country_code,geo,proper noun,place_type', three. Lastly, the 'next_token' parameter is used to go the adjacent 'page' of results. The value used in the parameter is pulled directly from the response provided by the API if more results than the cap per asking exist, we will talk more about this as nosotros go in this article.
'next_token': {} At present that we know what the create_url function does, a couple of important notes:
- Required endpoints:
In the case of the full-archive search endpoint, the *query* parameter is the only parameter that is **required** to make a request. E'er make certain to look at the documentation for the endpoint you are using to confirm which parameters Accept to exist and then y'all do non confront bug.
- Query Parameter:
The query parameter is where yous put the keyword(south) yous want to search for.
Queries can exist as simple as searching for tweets containing the give-and-take "xbox" or as circuitous as "(xbox europe) OR (xbox usa)" which will return tweets that contain the words xbox AND europe or xbox AND united states.
Also, a *query* can be customized using *search operators*. There are so many options that assist yous narrow your search results. We will hopefully talk over operators more in-depth in another article. For now, you can find the full list of operators for building queries here.
Example of a simple query with an operator: "xbox lang:en"
- Timestamps:
The end_time and start_time format that Twitter uses for timestamps is
YYYY-MM-DDTHH:mm:ssZ (ISO 8601/RFC 3339)
So brand certain to convert the dates yous want to this format. If you are unsure well-nigh how to, this is a nice timestamp converter that will definitely help.
- Results book:
The number of search results returned past a request is currently express between 10 and 500 results.
Now y'all might be asking, how can I get more than 500 results then? That is where *next_token* and pagination come to play!
The answer is simple: If more than results exist for your query, Twitter will render a unique next_token that yous can utilize in your next request and information technology will give y'all the new results.
If you want to remember all the tweets that exist for your query, you just keep sending requests using the new *next_token* you receive every fourth dimension, until no next_token exists, signaling that you take retrieved all the tweets!
Hopefully, you are not feeling too dislocated! Only don't worry, when we run all of the functions we simply created, it will exist clear!
half dozen. Connect to Endpoint
Now that we accept the URL, headers, and parameters we desire, we will create a function that will put all of this together and connect to the endpoint.
The function below will send the "Get" request and if everything is correct (response code 200), it will return the response in "JSON" format.
Note: next_token is set to "None" past default since nosotros only care about information technology if it exists.
7. Putting it all Together
Now that we have all the functions nosotros need, permit'due south test putting them all together to create our first asking!
In the next cell, we will set upward our inputs:
- bearer_token and headers from the API.
- Nosotros will look for tweets in English that contain the word "xbox".
- We will look for tweets between the 1st and the 31st of March, 2021.
- We want just a maximum of 15 tweets returned.
Now we will create the URL and go the response from the API.
The response returned from the Twitter API is returned in JavaScript Object Notation "JSON" format.
To be able to deal with it and break down the response we get, we will the encoder and decoder that exists for python which we have imported earlier. You can find more information about the library here.
If the returned response from the beneath code is 200 , and so the asking was successful.
url = create_url(keyword, start_time,end_time, max_results) json_response = connect_to_endpoint(url[0], headers, url[1])
Lets print the response in a readable format using this JSON library functions
impress(json.dumps(json_response, indent=4, sort_keys=True)) Now let's break down the returned JSON response, the response is basically read as a Python dictionary and the keys either contain data or comprise more dictionaries. The meridian ii keys are:
A. Data:
A listing of dictionaries, each dictionary represents the information for a tweet. Case on how to retrieve the time from the first tweet was created:
json_response['data'][0]['created_at'] B. Meta:
A dictionary of attributes about the request we sent, we normally would just care about two keys in this dictionary, next_token and result_count.
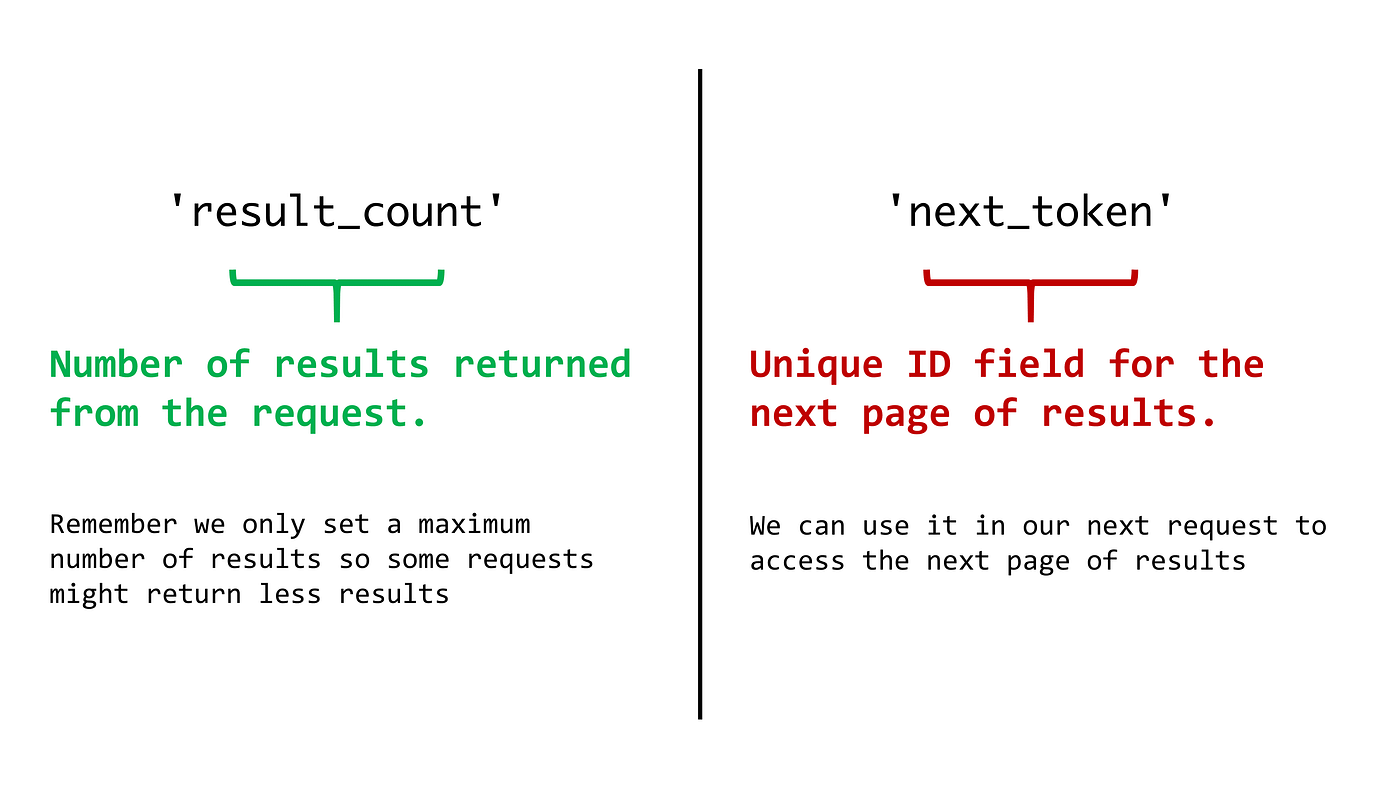
To call back the next_token for case, you can write:
json_response['meta']['result_count'] Now we have ii options to save results depending on how we want to deal with the data, either nosotros can save the results in the aforementioned JSON format we received, or in CSV format.
To save results in JSON, we can hands do information technology using these two lines of code:
with open('data.json', 'due west') equally f:
json.dump(json_response, f) 8. Save Results to CSV
You might be asking yourself, why exercise we want to save the results in CSV format? The short answer is, compared to a JSON object, CSVs are a widely used format that can easily be imported into an Excel spreadsheet, database, or data visualization software.
Now, to salvage the results in a table format for CSV, in that location are two approaches, a elementary approach and a more than custom approach.
Well… If there is a simple approach through a Python library, why do we need the custom approach?
The respond to that is: The custom function will brand us break downwardly and streamline the embedded dictionaries in some of the returned results into separate columns, making our analysis task easier.
For case, the public metrics key:
"public_metrics": {
"like_count": 0,
"quote_count": 0,
"reply_count": 0,
"retweet_count": 0
}, The key returns another dictionary, the simple arroyo will relieve this dictionary under one CSV cavalcade, while in the custom approach, we tin break each into a dissimilar column before saving the data to CSV.
A. The simple approach:
For this approach, we volition be using the Pandas package
df = pd.DataFrame(response['json_response'])
df.to_csv('information.csv') This is based on content from this blog post from the Twitter Dev team on this topic, which I tried and it works really well with uncomplicated queries.
B. The custom arroyo:
First, we will create a CSV file with our desired column headers, nosotros will do this separately from our actual office so afterward on it does not interfere with looping over requests.
And then, nosotros volition create our append_to_csv function, which nosotros will input the response and desired filename into, and the function volition append all the information nosotros nerveless to the CSV file.
Now if we run our append_to_csv() role on our concluding call, we should accept a file that contains 15 tweets (or less depending on your query)
append_to_csv(json_response, "data.csv") 9. Looping Through Requests
Good task! We take sent our first request and saved the first response from it.
Now, what if we want to salvage more responses? Across the showtime 500 results that Twitter gave the states or if we want to automate getting Tweets over a specific menstruation of time. For that, we will be using loops and the next_token variables we receive from Twitter.
Let'southward remember about this example:
We want to collect tweets that contained the word "COVID-nineteen" in 2020 to analyse people'due south sentiment when tweeting nearly the virus. Probably millions of tweets exist, and we have a limit of collecting x Meg tweets per calendar month only.
If we just transport a request to collect tweets between the 1st of January 2020 and the 31st of December 2020, we will hit our cap very apace without having a good distribution from all 12 months.
And then what nosotros can practise is, we can set a limit for tweets we want to collect per month, so that if we accomplish the specific cap at one month, we move on to the next ane.
The code beneath is an case that will just do that exactly! The block of code beneath is composed of two loops:
- A For-loop that goes over the months/weeks/days we want to encompass (Depending on how it is fix)
- A While-loop that controls the maximum number of tweets we desire to collect per time catamenia.
Find that a time.sleep() is added betwixt calls to ensure you are not just spamming the API with requests.
Summary
In this article, we have gone through an extensive step-by-step procedure for collecting Tweets from Twitter API v2 for Academic Research using Python.
We have covered the pre-requisites required, authentication, creating requests and sending requests to the search/all endpoint, and finally saving responses in different formats.
If you liked this, experience costless to share it with your friends and colleagues over Twitter and LinkedIn!
Feel free to connect with me on LinkedIn or follow me on Twitter!
Source: https://towardsdatascience.com/an-extensive-guide-to-collecting-tweets-from-twitter-api-v2-for-academic-research-using-python-3-518fcb71df2a
0 Response to "How to Prevent Twitter Api From Retrieving Same Tweets Again and Again"
Post a Comment